因為現在很多人在做自己的論壇,為了對他們有些幫助,我打算把我最佳化論壇的步驟寫下來。 文章會分為好幾篇來寫,由於涉及的細節很多,我自己也是在邊寫帖子邊給論壇做 SEO 最佳化,所以我也不知道會寫到什麼時候結束。
1,選擇論壇程式和版本。
我選擇的論壇程式是 Discuz! x1.5,語言版本是 gbk 版。為什麼選這個版本呢?
首先 Discuz!x1.5 的使用者體驗要比 Discuz!7.2 好很多,大家慢慢用這個論壇就會發現這一點。然後 Discuz!x1.5 的 SEO 基礎也要比 Discuz!7.2 好。其實 Discuz!7.2 是有很多 SEO 上面的缺陷的,以前那個老論壇我想做一下 SEO 最佳化,但是發現要改的還真不少。但是 Discuz!x1.5 注意到了很多對 SEO 不友好的地方,如很多容易產生重複的連結就用 JS 呼叫等等。
顯然 Discuz! x1.5 的開發團隊做事非常用心,讓我也對改這個論壇程式有信心很多。
那為什麼要選 GBK 版本而不選 UTF8 版本呢? 這是為了讓中文搜尋引擎第一時間知道我網站上的內容是中文版本。
爬蟲在 GBK 編碼的網頁,看到的是:
| <html xmlns="http://www.w3.org/1999/xhtml"><head>
<meta http-equiv="Content-Type" content="text/html; charset=gbk" /> |
而在 utf-8 編碼的網頁看到的是:
| <html xmlns="http://www.w3.org/1999/xhtml">
<head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> |
Utf-8 編碼的網頁,一時半會還真不知道這個網站裡的內容是什麼語言的,而且如果一個網頁中有中文和有英文的時候,搜尋引擎還要根據其他一些條件來判斷網站的語言版本。而 GBK 版本一看就知道是中文的了。
大家如果去檢視一下的話,Discuz 官方論壇用的就是 GBK 版本。
那已經在用 utf-8 的中文 discuz 論壇怎麼辦呢? 其實還是有方法解決的,可以定義一下 xmlns 屬性,把 lang="zh-CN" 加在裡面就可以了。 所以 utf-8 版本的程式碼變為:
| <html xmlns="http://www.w3.org/1999/xhtml" lang="zh-CN"> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> |
Discuz 論壇很多檔案都需要這麼改,可以用 Dreamweaver 整站查詢一下。很多其他網站也一樣。這樣改好後,搜尋引擎能識別這個網頁為簡體中文版。
2,選擇伺服器系統
我是很早就不想用 windows 做伺服器作業系統了,只要體會過 linux 系統好處的人恐怕都是如此。其實,選擇什麼樣的伺服器系統也能影響 SEO 效果的。我最近給很多大中型網站做 SEO 顧問的時候據發現一個很有趣的規律: 凡是用 windows 類系統搭建的網站,SEO 方面的表現都是不太理想的,而且要最佳化起來難度也是大一些的。
原因是很多方面的,因為 windows 類主機不是很穩定,只要程式設計師不那麼熟悉整個網站,要麼被動的頻繁當機、要麼需要主動停機維護、要麼資料庫壓力大以及執行的程式碼先天不足導致伺服器速度非常慢。 我觀察過很多網站的爬蟲訪問情況,在同等條件下,windows 類主機的抓取量都是差一些的。
當然,這個問題在一個資深的技術人員手裡都不是問題,但就是優秀的技術人員實在太難找到了。
3 、最佳化網站的訪問速度
網頁的載入速度對 SEO 影響比較大。最佳化網站的載入速度,可以從以下幾個方面來最佳化。
1)DNS
2) 伺服器網路環境
3) 伺服器硬體和系統
4) 網站程式或 CMS
5) 前端程式碼
這些因素不用去記的,基本上就是看爬蟲從發起一個請求到返回資料,中間需要經過哪些途徑,然後最佳化這些相關因素即可。
現在這個論壇只最佳化了 2 個地方,就是是 DNS 最佳化和網頁開啟 GZIP 壓縮。因為用的是現成的程式,其他地方都不太差,暫時先解決一些基本的問題。
DNS 上的最佳化,就是啟用了雙線主機以及智慧 DNS 。 為什麼我要先做這個呢? 因為我想最佳化百度爬蟲訪問我網站的速度。
§
因為這是中文論壇,做 SEO 最佳化肯定要以百度優先。
因為很多人還是沒有養成先看資料再來做 SEO 的意識,所以在最佳化速度的過程,有個問題沒注意到的。這就是沒有看看爬蟲到底是從什麼地方來訪問的。 對於大部分中文網站來說,爬蟲可能 90% 以上都是從北京聯通 (網通) 訪問過來的。這個時候就要特別最佳化北京聯通 (網通) 的訪問速度。
所以我用的雙線機房有 2 個 IP,一個電信的 IP 和一個聯通 (網通) 的 IP 。有了個 2 個 IP,還要做智慧 DNS,這樣當電信的使用者訪問論壇的時候,就解析到電信的 IP 上,聯通的使用者訪問論壇的時候就解析到聯通 (網通)IP 上。 這樣,百度爬蟲從北京聯通訪問我論壇的時候,速度就快很多了。 我用的智慧 DNS 服務是 DNSPod(http://www.dnspod.com/) 提供的,設定的介面如下:
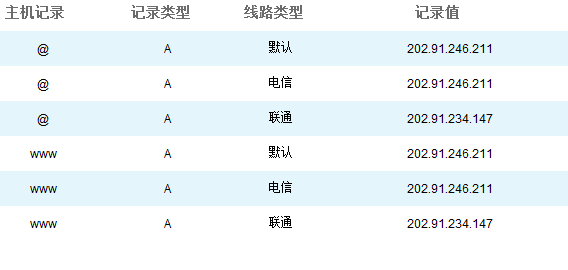
我在 DNSPod 裡面的賬戶是免費賬戶,收費賬戶應該速度更好一點,但是 DNSPod 對於收費賬戶還要稽核,我就一直沒升級了。
設定好了以後,還要檢查一下到底最佳化的效果如何。 可以用監控寶 (http://www.jiankongbao.com/) 的工具檢測一下。以前北京聯通的響應速度是 1831 ms 。經過最佳化,速度確實會提高很多,如:
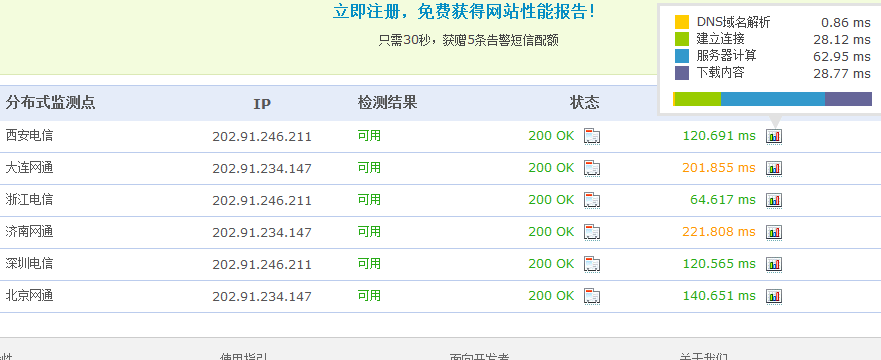
這裡還列出了是哪方面影響速度的因素大。最好是長期監測這個響應速度,因為這個因素的變化能比較大的影響到 SEO 效果。可以註冊成為這個網站的付費使用者,就可以每隔幾分鐘去檢測一下網頁的響應時間等等。
為了加快前端的速度,我啟用了論壇自帶的 gzip 壓縮。 Discuz!x1.5 後臺現在還沒有啟用 gzip 壓縮功能的地方,需要手動設定:
開啟 /config/config_global.php 檔案,把
| $_config['output']['gzip'] = '0'; |
改為
| $_config['output']['gzip'] = '1'; |
即可啟用 gzip 壓縮。
Discuz! x1.5 後臺還可以做一些速度上的最佳化如啟用 memcache 等等,但是這個相對麻煩點,留著下次來做。
4,靜態化 URL
Discuz! x1.5 後臺自帶了一個靜態化 URL 的功能,而且預設也寫好了靜態化的規則。但是這裡有一個問題,就是帖子頁面的靜態化規則沒有寫好。
如預設的帖子頁面規則是:
| thread-{tid}-{page}-{prevpage}.html |
即規則為:
| thread-{帖子 ID}-{帖子翻頁 ID}-{當前帖子所在的列表頁 ID}.html |
問題就出在 「當前帖子所在的列表頁 ID」 這裡,因為在論壇板塊中,當一個帖子是最新發表或最新回覆的時候,「當前帖子所在的列表頁」 是第一頁,url 中的數字是 「1」 。當這個帖子很久沒人回覆沉下去的時候,「當前帖子所在的列表頁」 就不知道是幾了,可能出現在第二頁,也可能在第十頁。這樣,每個帖子的 url 經常在變化。會產生很多的重複頁面,而且 url 經常變化,當前帖子積累的權重會丟失。
為瞭解決這個問題,可以重寫 url 靜態化規則。當然修改頁面程式碼也能解決這個問題,但是不方便維護,因為修改後的檔案以後可能會被升級檔案覆蓋,而且會丟失部分功能。
論壇用的是 linux+apache,而且論壇是作為一個虛擬主機放在伺服器上。 Url 靜態化的過程就這麼操作:
新建一個文字檔案,檔名為 「.htaccess」,然後用 UltraEdit 編輯這個檔案,寫入的規則為:
| # 將 RewriteEngine 模式開啟 RewriteEngine On # 修改以下語句中的 RewriteBase 後的地址為你的論壇目錄地址,如果程式放在根目錄中,為 /,如果是相對論壇根目錄是其他目錄則寫為 /{目錄名},如:在 bbs 目錄下,則寫為 /bbs # Rewrite 系統規則請勿修改 |
用 UltraEdit 寫好規則後,按 F12,在檔案另存為的視窗上,有個 「格式」 選項,選 「utf-8 -無 BOM 「儲存。然後把 「.htaccess」 上傳到論壇根目錄。
§
然後在進入後臺 --> 全域性--> 最佳化設定--> 搜尋引擎最佳化 。 其他保持不變,就把 「主題內容頁」 規則改為:

儲存設定再更新一下快取就可以了。
5,解決重複 URL 的問題和遮蔽垃圾頁面
Discuz! X1.5 還是不可避免的出現重複 url 的問題。 (希望有渠道的朋友能把這些問題反饋給 Discuz 相關人員)
這些重複的 url 即浪費了爬蟲大量的時間,又使網站的原創性受到損害。所以一定要遮蔽很多重複頁面。
另外還要幹掉一些垃圾頁面,所謂垃圾頁面就是一些沒什麼 SEO 價值的頁面,也幫助爬蟲節約時間。
解決這個問題,最好是用 robots.txt 檔案來解決。因為裡面的規則是最強勢的,所有爬蟲第一次訪問一個域名,第一個動作都是下載這個 robots.txt 檔案並讀取裡面的規則。 其他一些 nofollow 和 rel=canonical 等標籤適當的時候再用。
雖然 Discuz 預設寫了一些 robots 規則,但是還是不夠理想。
根據從首頁的程式碼中發現的問題,需要在 robots.txt 裡增加的規則有:
| Disallow: /forum.php$ Disallow: /search-search-adv-yes.html Disallow: /space-username-* Disallow: /forum.php?gid= Disallow: /home.php?mod=space&username= Disallow: /forum.php?showoldetails= Disallow: /home-space-do-friend-view-online-type-member.html Disallow: /space-uid-* |
根據在板塊帖子列表頁面發現的問題,需要在 robots.txt 裡增加的規則有:
| Disallow: /search.php$ Disallow: /forum-forumdisplay-fid-* |
根據在帖子詳細資訊頁面看到的問題,需要在 robots.txt 裡增加的規則有:
| Disallow: /forum-viewthread-tid-*-extra-page%3D.html$ Disallow: /forum.php?mod=viewthread&tid= Disallow: /forum-viewthread-tid-*-page-*-authorid-*.html Disallow: /forum-viewthread-tid-*-extra-page%3D-ordertype-*.html Disallow: /forum-viewthread-action-printable-tid-*.html Disallow: /home-space-uid-* |
至於為什麼要寫這些規則,由於描述起來實在囉嗦,所以大家自行到原始碼裡檢視為什麼。
robots 的寫法是很靈活的。
可以看一下百度的 robots 寫法指南:
http://www.baidu.com/search/robots.html
以及 google 網站管理員中心的說明:
http://www.google.com/support/webmasters/bin/answer.py?hl=cn&answer=156449
robots.txt 寫到這裡並不是結束,還有兩件事情要做。
1,因為 robots.txt 和 nofollow 是不同的意思,所以 robots.txt 並不能代替 nofollow 。以上這些需要遮蔽的地方還需要用 nofollow 標註一下。 不過因為要改的原始碼太多,暫時先不動。需要用 nofollow,還有一個原因是某些搜尋引擎並不遵守自己所定下的 robots 規則。
2,因為只看過論壇中的三類主要頁面,還有很多頁面沒檢視過,難免會有漏掉的地方,所以需要以後經常到日誌中檢視爬蟲的軌跡,看看爬蟲還有哪些抓取問題。